
Topics¶
- Input Representation
- Convolutional Neural Networks
- Convolution, Activation, Pooling
- Architectures
- Image Classification
- Object Detection
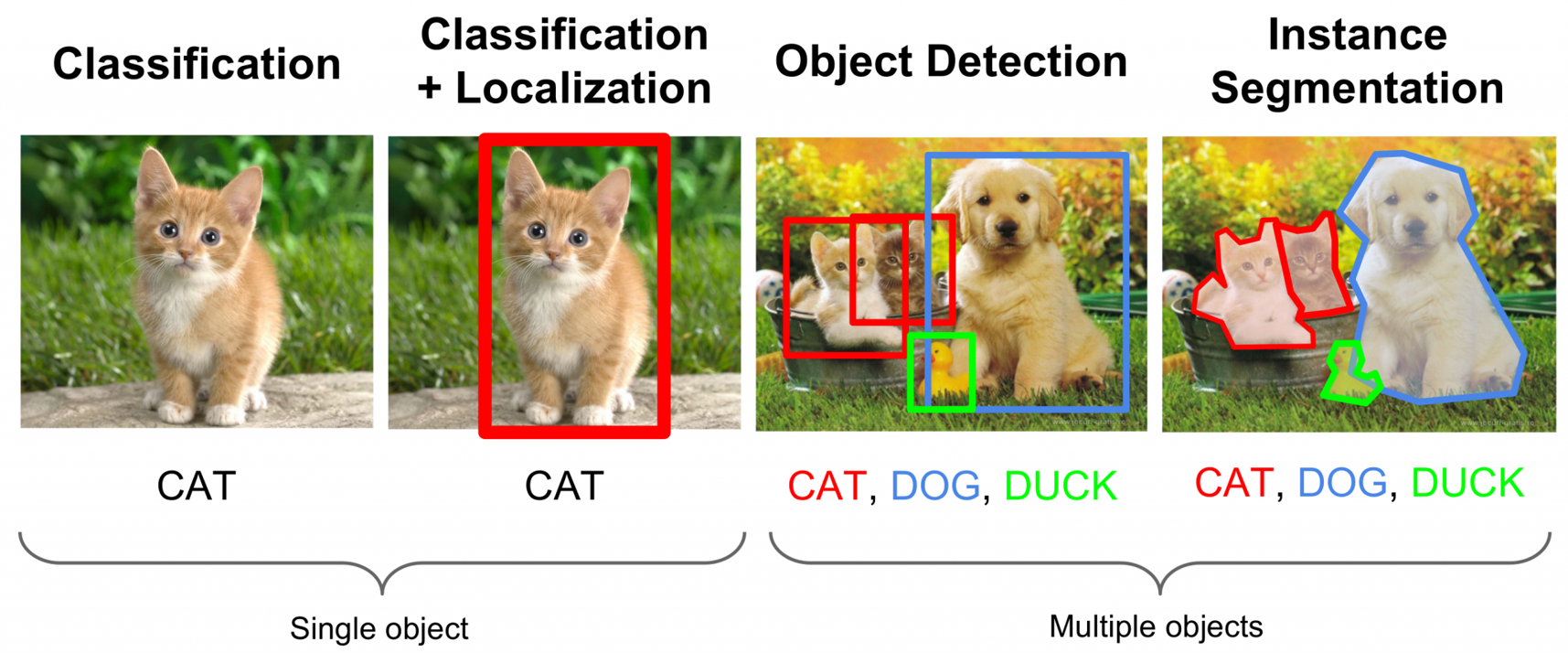
Image Representation: Tensor¶
- 3 channels: 'rgb'
- rows: image height
- columns: image width
Ordering:
- Channels-first: channel, rows, columns
- Channels-last: rows, columns, channels
Walkthrough - Image Tensors¶
In this walkthrough, we will read an image from file and examine the data.
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
# read an image file
demo = Image.open('assets/image/cat.jpg') # source: pxhere.com/en/photo/1337399
# check whether this is RGB or BGR
# so that we can input the images correctly to our neural network
print('channel ordering:', demo.mode)
# display the image
plt.imshow(demo)
plt.title('moar food')
plt.show()
# examine the numpy array
demo_arr = np.array(demo)
print('shape:', demo_arr.shape)
print('data type:', demo_arr.dtype)
print('rank:', demo_arr.ndim)
# since the sides of the picture are the same boring color
# inspect the (roughly) middle 5 rows and columns
midpoint_row = int(demo_arr.shape[0] / 2)
midpoint_col = int(demo_arr.shape[1] / 2)
demo_arr[midpoint_row:midpoint_row+5, midpoint_col:midpoint_col+5, :]
# resize the image to 224 by 224
demo.thumbnail((224, 224), resample=Image.BICUBIC)
# display the image
plt.imshow(demo, interpolation='nearest')
plt.title('moar smaller (224x224)')
plt.show()
# examine the numpy array again
demo_arr = np.array(demo)
print(demo_arr.shape)
print(demo_arr.dtype)
# notice the difference in values from previously
midpoint_row = int(demo_arr.shape[0] / 2)
midpoint_col = int(demo_arr.shape[1] / 2)
demo_arr[midpoint_row:midpoint_row+5, midpoint_col:midpoint_col+5, :]
A histogram is sometimes helpful to visualize the colour distribution of a given channel
# order: RGB
red_channel = demo_arr[:, :, 0]
green_channel = demo_arr[:, :, 1]
blue_channel = demo_arr[:, :, 2]
fig, ax = plt.subplots(nrows=1, ncols=3, figsize=(20, 10))
# flatten the [row_size, col_size] matrix into a vector of [row_size * col_size]
# we just need to count the raw pixel values for the histogram,
# so it doesn't matter where they are located.
ax[0].hist(red_channel.flatten(), 256, range=(0,256), color='red')
ax[1].hist(green_channel.flatten(), 256, range=(0,256), color='green')
ax[2].hist(blue_channel.flatten(), 256, range=(0,256), color='blue')
fig.suptitle('Histogram of input image')
plt.show()
Output¶
- Image Classification: labels
- Object Detection: labels + bounding boxes
- Instance Segmentation: labels + boundaries
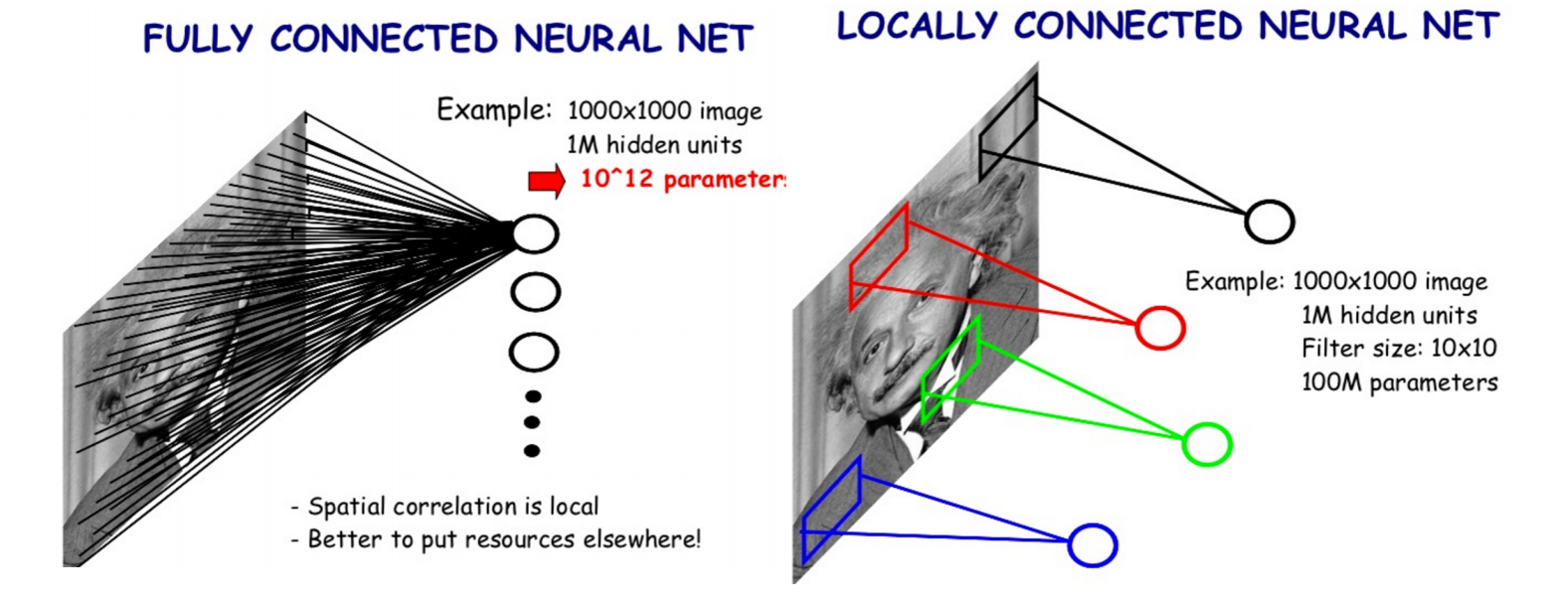
Problem: many input features $\rightarrow$ many parameters¶
224 x 224 pixel colour image: 224 x 224 x 3 = 150528 features
Dimensionality reduction may help, but there's a better way....
Convolution¶
- Reduces parameter space
- Looks at localized, spatial information
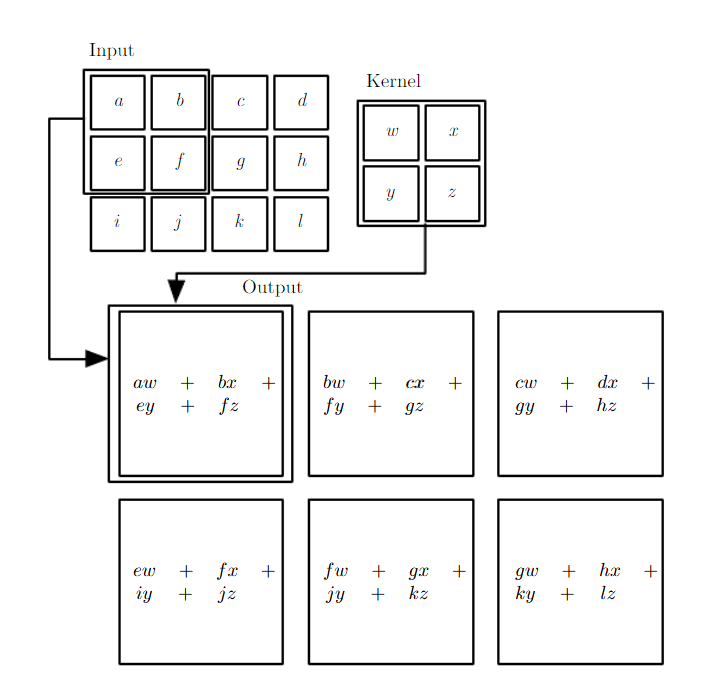
(image: leonardoaraujosantos.gitbooks.io)
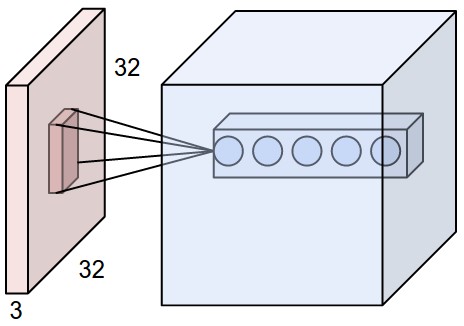
Convolution - Hyperparmeters¶
- Kernel size: size of the window (pixels)
- Stride: how many pixels to slide the window
- Depth: how many filters to use
- Padding: whether to keep the output size the same as input size
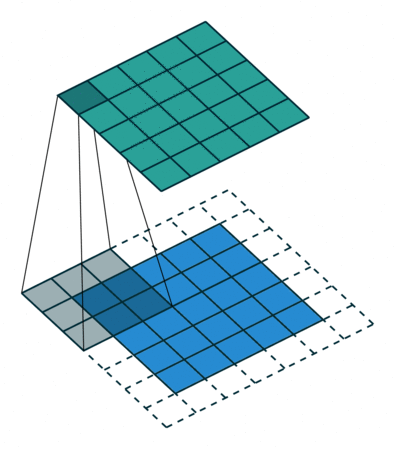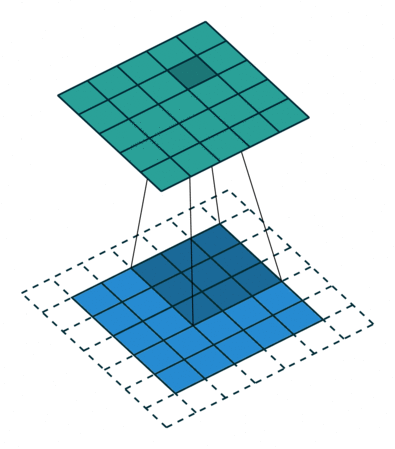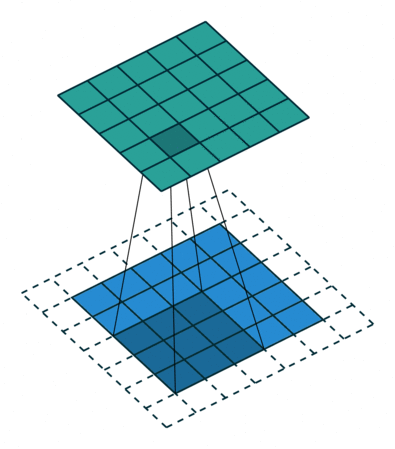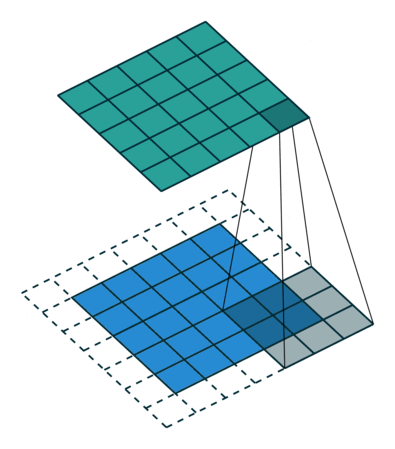
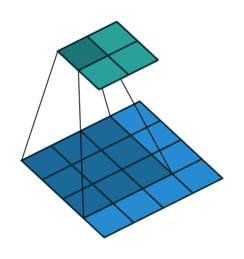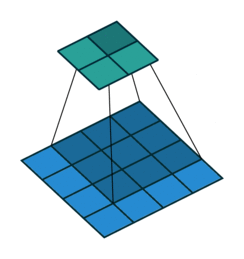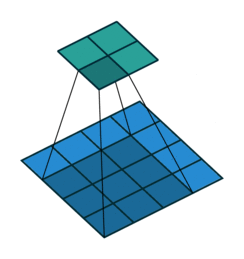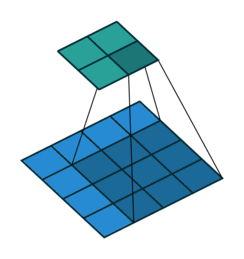
Activity - Convolution Hyperparameters¶
Run and watch the example in the next cell.
Fill in the corresponding hyperparameters
- Kernel Size =
- Stride =
- Depth =
- Padding =
# Source: https://cs231n.github.io/convolutional-networks
from IPython.display import HTML
HTML('<iframe src=conv-demo.html width=800 height=700></iframe>')
Walkthrough - 2D Convolution¶
In this walkthrough, we will convolve our demo image with a kernel that performs edge detection.
Credits: http://machinelearninguru.com/computer_vision/basics/convolution/image_convolution_1.html
# convert our input image to greyscale (1 channel)
demo_grey = demo.convert(mode='L')
plt.imshow(demo_grey, interpolation='nearest')
plt.title('moar grey')
plt.show()
# https://docs.scipy.org/doc/scipy/reference/generated/scipy.signal.convolve2d.html
from scipy.signal import convolve2d
# edge-detection kernel
kernel = np.array([[-1,-1,-1],[-1,8,-1],[-1,-1,-1]])
# we use 'valid' which means we do not add zero padding to our image
edges = convolve2d(demo_grey, kernel, mode='valid')
plt.imshow(edges)
plt.title('moar edges')
plt.show()
Convolutional Block¶
Generally, 3 stages:
- Convolutional Layer
- Activation Layer
- Pooling Layer
Sometimes 1 & 2 will repeat a few times before 3.
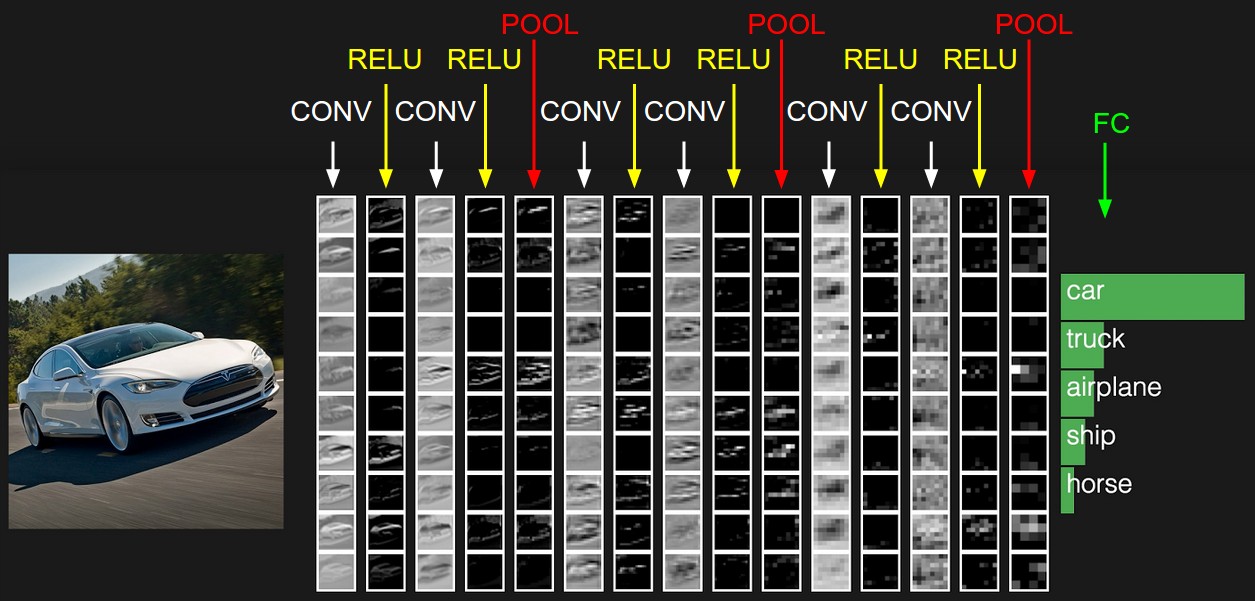
Activation Layer¶
The output of convolution is typically passed through an "activation" function, so that it can model non-linearity:
Examples:
- linear (= no activation)
- sigmoid
- tanh
- Rectified Linear Units, leaky ReLU, Parametric ReLU, Exponential Linear Units
Walkthrough - Activation Functions¶
Let's see what happens when we pass our convolved edge detected image through various activation functions.
import numpy as np
input_arr = edges
input_arr.shape
Sigmoid
$f(x) = \frac{1}{1 + e^{-x}}$
def sigmoid(x):
return 1 / (1 + np.exp(-x))
plt.imshow(sigmoid(edges))
plt.title('edges + sigmoid')
plt.show()
# inspect somewhere in the middle of image (that's not black)
input_arr[112:114]
sigmoid(input_arr[112:114])
plt.imshow(np.tanh(input_arr))
plt.title('edges + tanh')
plt.show()
input_arr[112:114]
sigmoid(input_arr[112:114])
ReLU
$f(x) = max(0, x)$
def relu(x):
return np.maximum(x, 0)
plt.imshow(relu(input_arr))
plt.title('edges + ReLU')
plt.show()
input_arr[112:114]
relu(input_arr[112:114])
Leaky ReLU
$f(x) = \begin{cases} x & if\,x > 0 \\ 0.01x & otherwise \end{cases}$
def leaky_relu(x):
return np.where(x > 0, x, x * 0.01)
plt.imshow(leaky_relu(input_arr))
plt.title('edges + Leaky ReLU')
plt.show()
leaky_relu(input_arr[112:114])
Pooling Layer¶
- Summarizes the activations
- Take the maximum of a window size: Max pooling
- Take the average of a window size: Average pooling
Pooling Layer¶
- Translation invariances:
- Robust to shifts in locations of pixels within that window
- Downsampling:
- Compressing and summarizing inputs into next layers
- Pass the highest activation, or the average activations to the next layer
# https://stackoverflow.com/questions/42463172/how-to-perform-max-mean-pooling-on-a-2d-array-using-numpy
from skimage.measure import block_reduce
def max_pool(x, pool_size=(2, 2)):
return block_reduce(x, pool_size, np.max)
def average_pool(x, pool_size=(2, 2)):
return block_reduce(x, pool_size, np.mean)
plt.imshow(max_pool(sigmoid(edges)))
plt.title('edges + sigmoid + max pool')
plt.show()
print('Original shape:', edges.shape)
print('After activation:', sigmoid(edges).shape)
# (2, 2) will halve the size of the output
print('After max pooling (2, 2):', max_pool(sigmoid(edges)).shape)
Max Pool¶
pool_size=(2, 2) means that it takes a 2x2 square and outputs 1 number.
The number is the maximum of the 4 numbers in that 2x2 square.
If the size is not divisible by pool_size, there are two choices:
- With zero padding: pad by zeros to make the size divisible. Then perform MaxPooling operation
- Without zero padding: behavior is not defined. Some libraries will drop these "edge" values.
edges[70:71] # somewhere in middle of image
sigmoid(edges)[70:71]
max_pool(sigmoid(edges))[70:71]
print('Before maxpool', sigmoid(edges)[70:71].shape)
print('After maxpool (shape / 2)', max_pool(sigmoid(edges))[70:71].shape)
Average Pool¶
pool_size=(2, 2) means that it takes a 2x2 square and outputs 1 number.
The number is the average of the 4 numbers in that 2x2 square.
If the size is not divisible by the pool size, there are two choices:
- With zero padding: pad by zeros to make the size divisible. Then perform MaxPooling operation
- Without zero padding: behavior is not defined. Some libraries will drop these "edge" values.
plt.imshow(average_pool(sigmoid(edges)))
plt.title('edges + sigmoid + average pool')
plt.show()
plt.imshow(max_pool(relu(edges)))
plt.title('edges + relu + max pool')
plt.show()
plt.imshow(average_pool(relu(edges)))
plt.title('edges + relu + average pool')
plt.show()
Regularization Layers¶
These layers are common in Deep Convolutional Neural Networks:
- Dropout
- Batch Normalization
Dropout¶
- Randomly setting some layer inputs to 0 during training to reduce overfitting.
- No-op during prediction
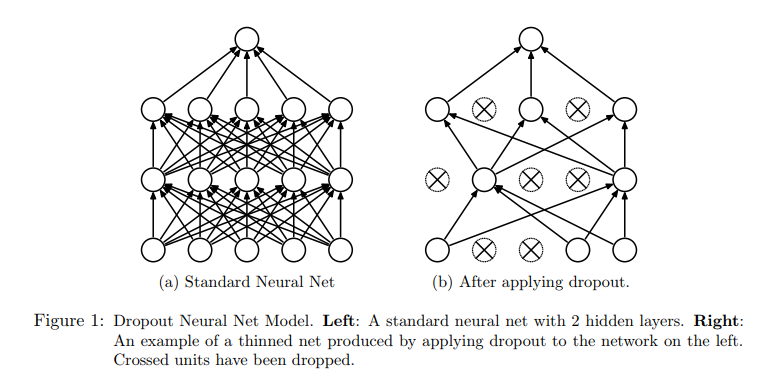
Batch Normalization¶
- Avoid saturating non-linearities by normalizing the input to the next layer
- Normalizing is done per minibatch
- Speeds up training

Batch Normalization - Prediction¶
- Minibatch mean and variance don't apply at prediction time
- Instead, "population" mean and variance is computed and stored from training
- Batch Norm layer will use the population mean and variance for prediction
Architectures¶
- Image Classification
- Object Detection
- Instance Segmentation
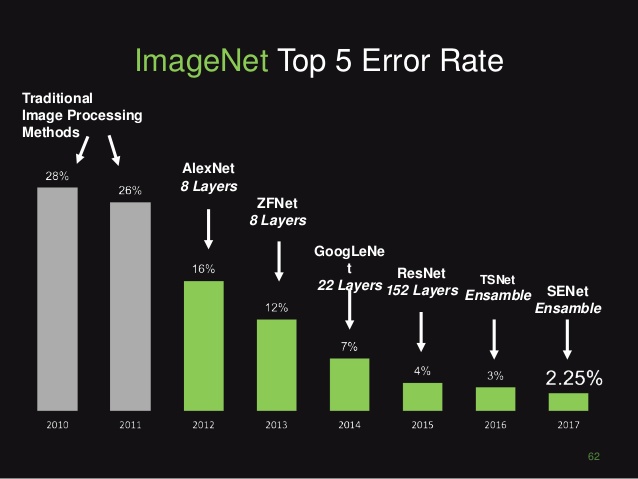
ImageNet Large Scale Visual Recognition Challenge (ILSVRC)¶
- http://image-net.org/index
- 14 million crowdsourced, hand-annotated images
- Annual challenge, since 2010
- Classifiy images into 1000 classes (including 90 dog breeds)
- CNN breakthrough in 2012
Workshop: Image Classification CNNs¶
In this workshop, we'll explore a couple of Convolutional Neural Networks (CNNs) that are trained for ImageNet to perform accurate image classification.
We'll classify an image with the VGG16 model.
Documentation: https://keras.io/applications/#vgg16
Implementation: https://github.com/keras-team/keras-applications/blob/master/keras_applications/vgg16.py
Note that the weights are stored separately from the implementation.
from keras.applications import VGG16
vgg16 = VGG16()
print(vgg16.summary())
Download Image¶
- Download an image from the web. It can be any well-known image format such as PNG or JPEG.
- Update the
pathvariable to point to your image
# update this path to your own image
path = 'assets/image/cat.jpg'
Pre-process image¶
- Resize the crop the image into height: 224, width: 224
- These dimensions are specified by the neural network as the default input size
- Pre-process the image using
VGG16.preprocess_input - Prepend an extra axis to match the input shape that the model expects
def resize_and_crop_image(image_path, width, height):
"""Resizes and crops an image to the desired size
Args:
image_path: path to the image
width: image width
height: image height
Returns:
the resulting image
"""
from PIL import Image, ImageOps
img = Image.open(image_path)
img = ImageOps.fit(img, (width, height))
return img
# Preprocess image input
import numpy as np
from keras.preprocessing.image import img_to_array
from keras.applications.vgg16 import preprocess_input, decode_predictions
img = resize_and_crop_image(path, 224, 224)
x = img_to_array(img)
x = preprocess_input(x)
print('Original image shape:', x.shape)
# The model expect images in a batch, because it's trained that way
# Add an extra first axis
x = np.expand_dims(x, axis=0)
print('Expected input shape', x.shape)
Predict and decode predictions¶
- Run the
VGG16.predictmethod on the pre-processed image. - Use the
VGG16.decode_predictionsmethod to translate the raw predicted values into class labels.
y = vgg16.predict(x)
# display the image
plt.imshow(img, interpolation='nearest')
plt.title('Test image')
plt.show()
# display the predictions
print('Raw predictions:')
print(y)
print('Decoded predictions:')
print(decode_predictions(y, top=5))
Exercise: Choose your own Image Classification CNN¶
- Pick another CNN from this list: https://keras.io/applications/#available-models
- Note: we are using models from
keras.applications. The next workshop will cover using a keras model from a third-party source.
- Note: we are using models from
- Repeat the steps above to:
- Examine the model by getting its summary
- Resize, crop, and preprocess the image using that model's
preprocess_inputmethod. - For best results, stick to the input size that is documented for the model
- Get raw predictions
- Decode the predictions using that model's
decode_predictionsmethod.
Can you find a model that performs better than VGG16?
# Your code here
Workshop: Object Detection CNN¶
In this workshop, we'll explore an Object Detection CNN.
Object detection CNNs are not part of keras.applications, so we need to download the models separately, and then load it into keras.
We'll try this model: https://github.com/qqwweee/keras-yolo3.
This is a keras wrapper for the YOLO (you only look once) v3 model: https://pjreddie.com/darknet/yolo/
Clone the keras-yolo3 repository¶
From a command window:
git clone https://github.com/qqwweee/keras-yolo3.gitDownload pre-trained YOLO v3 weights¶
Download https://pjreddie.com/media/files/yolov3.weights into your keras-yolo3 folder.
Note: This file is 237MB, and may take a few minutes to download. While we are waiting, you can run the next cell (Examine YOLO v3 architecture).
Examine YOLO v3 architecture¶
(This step can be done in parallel with the download.)
Open yolov3.cfg in the keras-yolo3 folder in a text editor.
Scroll through the file, and you should recognize a few keywords. This config file defines the YOLO v3 architecture.
Here's how the hyperparameters are set for one of the many convolutional blocks:
[convolutional]
batch_normalize=1
filters=64
size=3
stride=2
pad=1
activation=leakyThe above describes a convolutional block with:
- depth 64
- kernel size 3
- stride 2
- padding "same"
- batch normalization
- leaky ReLU activation
- no pooling layer
These design choices are specific to this architecture.
If successful, you should see this:
Parsing section yolo_2
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, None, None, 3 0
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, None, None, 3 864 input_1[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, None, None, 3 128 conv2d_1[0][0]
__________________________________________________________________________________________________
leaky_re_lu_1 (LeakyReLU) (None, None, None, 3 0 batch_normalization_1[0][0]
...
__________________________________________________________________________________________________
batch_normalization_72 (BatchNo (None, None, None, 2 1024 conv2d_74[0][0]
__________________________________________________________________________________________________
leaky_re_lu_58 (LeakyReLU) (None, None, None, 1 0 batch_normalization_58[0][0]
__________________________________________________________________________________________________
leaky_re_lu_65 (LeakyReLU) (None, None, None, 5 0 batch_normalization_65[0][0]
__________________________________________________________________________________________________
leaky_re_lu_72 (LeakyReLU) (None, None, None, 2 0 batch_normalization_72[0][0]
__________________________________________________________________________________________________
conv2d_59 (Conv2D) (None, None, None, 2 261375 leaky_re_lu_58[0][0]
__________________________________________________________________________________________________
conv2d_67 (Conv2D) (None, None, None, 2 130815 leaky_re_lu_65[0][0]
__________________________________________________________________________________________________
conv2d_75 (Conv2D) (None, None, None, 2 65535 leaky_re_lu_72[0][0]
==================================================================================================
Total params: 62,001,757
Trainable params: 61,949,149
Non-trainable params: 52,608
__________________________________________________________________________________________________
None
Saved Keras model to model_data\yolo.h5
Read 62001757 of 62001757.0 from Darknet weights.A few interesting things:¶
- This is a big model (62 million parameters)
- The architect of this network decided to insert batch normalization between the convolutional layer and its activation
- Pooling is not in use at all
Next, let's use the model to perform object detection on images and videos.
Image detection¶
python yolo.pyEnter an input image filename, and you should get something like this:

Video detection¶
Video detection works by processing the image, one frame at a time.
Setup - OpenCV¶
To run video detection, you need to install OpenCV
conda install opencvor
conda install -c conda-forge opencv[Optional] Setup - openh264¶
To display detection boxes embedded in the video, download the libopenh264 codec:
- Download https://github.com/cisco/openh264/releases
- Extract the .bz2 (on Windows, use Winzip or WinRAR)
- Copy openh264-1.6.0-win64msvc.dll to the
keras-yolo3folder
This is just for display purposes. The model will still detect objects without this.
Download a video (in the smallest resolution you can find), for example: https://pixabay.com/en/videos/street-it-s-raining-11067/
Run the video detector
python yolo_video.py video.mp4 output.mp4Here's an example output for an example video:
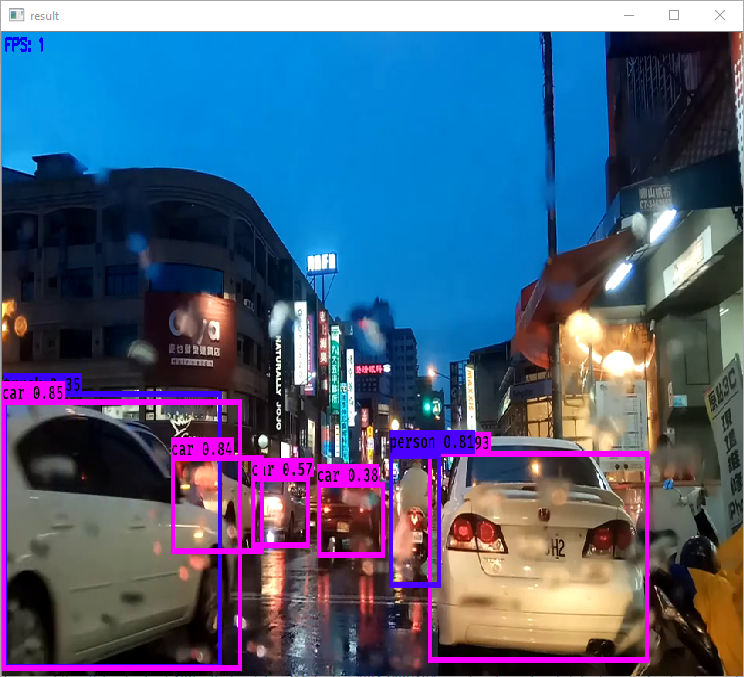
Found 7 boxes for img
truck 0.50 (19, 282) (250, 538)
car 0.46 (320, 374) (393, 435)
car 0.57 (221, 355) (343, 435)
car 0.65 (386, 381) (488, 442)
car 0.74 (19, 282) (250, 538)
car 0.92 (554, 354) (833, 526)
person 0.72 (498, 354) (566, 464)
3.7216578782751952
(416, 416, 3)
Found 6 boxes for img
car 0.51 (322, 374) (391, 434)
car 0.69 (386, 382) (485, 442)
car 0.77 (219, 354) (340, 435)
car 0.90 (16, 282) (260, 538)
car 0.92 (553, 353) (835, 526)
person 0.75 (499, 353) (566, 465)
3.7170675099385093
(416, 416, 3)
Found 6 boxes for img
car 0.70 (322, 375) (393, 434)
car 0.78 (390, 382) (483, 443)
car 0.86 (14, 285) (265, 539)
car 0.91 (220, 354) (338, 440)
car 0.92 (553, 353) (834, 527)
person 0.91 (495, 349) (565, 466)
3.7226787045414973
(416, 416, 3)
Found 7 boxes for img
truck 0.58 (9, 290) (268, 536)
car 0.68 (18, 304) (286, 524)
car 0.71 (323, 375) (395, 434)
car 0.86 (390, 382) (483, 444)
car 0.90 (219, 355) (340, 440)
car 0.92 (554, 354) (834, 527)
person 0.87 (495, 349) (565, 464)
3.609754515084603
(416, 416, 3)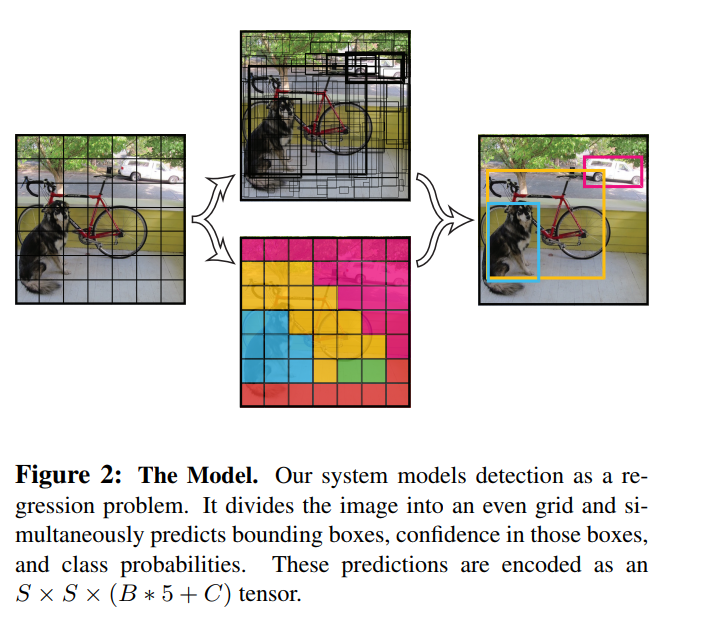
import os
keras_yolo3_path = 'D:/tmp/keras-yolo3/model_data' # update to your path
# trained weights
model_path = os.path.join(keras_yolo3_path, 'yolo.h5')
# anchors
anchors_path = os.path.join(keras_yolo3_path, 'yolo_anchors.txt')
# classes
classes_path = os.path.join(keras_yolo3_path, 'coco_classes.txt')
These are the pre-defined anchors, chosen to be representative of the ground truth detection boxes.
These are found using K-means clustering.
with open(anchors_path, 'r') as f:
print(f.read())
These are the classes of objects that the detector will recognize.
with open(classes_path, 'r') as f:
print(f.read())
Finally, this is the model architecture, as seen by keras.
from keras.models import load_model
# This file is really huge, so may take some time to load
yolo_model = load_model(model_path, compile=False)
yolo_model.summary()
Reading List¶
| Material | Read it for | URL |
|---|---|---|
| Deep Learning - Chapter 9.2: Motivation (p 329-335) | 3 motivations for convolution | http://www.deeplearningbook.org/contents/convnets.html |
| Deep Learning - Chapter 9.3: Motivation (p 335-339) | The idea behind pooling | http://www.deeplearningbook.org/contents/convnets.html |
| Bounding box object detectors: understanding YOLO, You Look Only Once | An overview of YOLO | https://christopher5106.github.io/object/detectors/2017/08/10/bounding-box-object-detectors-understanding-yolo.html |