
Setup¶
Create a new environment called mldds02. You may also reuse mldds01, but it's good to keep separate environments for different experiments.
From an Anaconda prompt:
conda create -n mldds02 python=3
conda activate mldds02
(mldds02) conda install jupyter numpy pandas matplotlib scikit-learn
(mldds02) conda install -c conda-forge ffmpeg
(mldds02) cd /path/to/mldds-courseware
(mldds02) jupyter notebookTopics¶
General concepts in training models
- Loss functions
- Gradient descent
- Overfitting, underfitting
- Regularization
- Cross-validation
Objective: a model that trains fast and performs well
Not an exhaustive list. We'll encounter more as we go over the different algorithms.
Loss Functions¶
What they are: a metric of how far away the predictions are from the truth
For example:

a.k.a.:
- Objective function
- Cost function
- Error function
Definitions¶
$$x^* = \arg \min L(x)$$
where $x^*$ = value that minimizes the loss function $L(x)$
The process of finding $x^*$ is called "Optimization". It usually involves running some type of Gradient Descent.
Loss Function Examples¶
Scikit-learn:
- Mean squared error:
sklearn.metrics.mean_squared_error(y_true, y_pred) - Log loss:
sklearn.metrics.log_loss(y_true, y_pred) - Zero one loss
sklearn.metrics.zero_one_loss(y_true, y_pred) - etc
Keras:
- https://keras.io/losses/
keras.losses.mean_squared_error(y_true, y_pred)keras.losses.binary_crossentropy(y_true, y_pred)- etc
# Plotting Log Loss
# Equation from: http://scikit-learn.org/stable/modules/generated/sklearn.metrics.log_loss.html#sklearn.metrics.log_loss
import numpy as np
import matplotlib.pyplot as plt
p = np.linspace(0.01, 0.99, 50) # avoid 0 and 1 because of div by zero
y_1 = np.ones(p.shape)
y_0 = np.zeros(p.shape)
# sklearn.metrics.log_loss returns a number, because
# it's a metric across test samples.
# So we implement our log_loss equation here:
def log_loss(y, p):
return -(y * np.log(p) + (1 - y) * np.log(1 - p))
fig, ax = plt.subplots(figsize=(15, 10))
ax.plot(p, log_loss(y_1, p), label='log loss for y=1')
ax.plot(p, log_loss(y_0, p), label='log loss y=0')
ax.legend()
Gradient Descent¶
What it is: technique for minimizing loss function for a given model
Objective: find $w^*$ such that $$w^* = \underset{w}\arg \min{L\big(y_{true}, y_{pred}\big)}$$
$$w^* = \underset{w}\arg \min{L\big(y_{true}, f(x, w)\big)}$$
where
- $L(...)$ is the loss function
- $w$ are the weights
- $f(x, w)$ is the model that computes $y_{pred}$
Gradient descent algorithm¶
- Initialize $w$ to some value (e.g. random)
- Compute gradient of $L\big(y_{true}, f(x, w)\big)$
- Update $w$ by a "tiny factor" in the negative of the gradient
- Repeat 2-3 until we reach the "stopping criteria" (more on this later)
The "tiny factor" is known as the "learning rate"
from IPython.display import YouTubeVideo
YouTubeVideo('kJgx2RcJKZY')
Learning Rate and Convergence¶
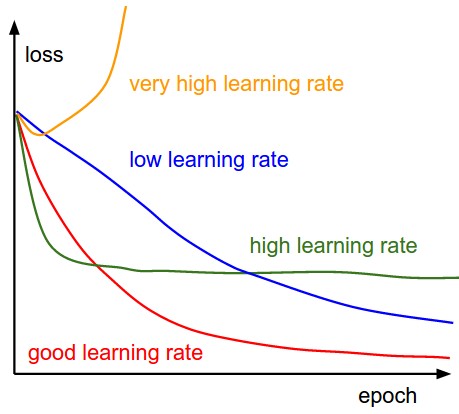
(image: https://leonardoaraujosantos.gitbooks.io/artificial-inteligence/content/model_optimization.html)
Workshop: Gradient descent. Animated¶
# Credits: https://jed-ai.github.io/py1_gd_animation/
import numpy as np
import matplotlib.pyplot as plt
"""Example gradient descent implementation"""
def func_y(x):
"""A demonstrative loss function that happens to be convex (has global a minimum)
Args:
x - the input (can be the weights of a machine learning algorithm)
Returns:
The loss value
"""
return x**2 - 4*x + 2
def gradient_func_y(x):
"""The gradient of func_y
Args:
x - the input
Returns:
The gradient value
"""
return 2*x - 4 # d(x^2 - 4x + 2)/dx = 2x - 4
def gradient_descent(previous_x, learning_rate, epochs):
"""An implementation of gradient descent
Args:
previous_x - the previous input value
learning_rate - how much to change x per iteration
epochs - number of steps to run gradient descent
Returns:
A tuple: array of x values, array of loss values
"""
x_gd = []
y_gd = []
x_gd.append(previous_x)
y_gd.append(func_y(previous_x))
# loop to update x and y
for i in range(epochs):
# x = lr * gradient(func(prev_x))
update = learning_rate *gradient_func_y(previous_x)
x = previous_x - update
print('step', i, 'previous x', previous_x,
'update:', -update, 'new x:', x)
x_gd.append(x)
y_gd.append(func_y(x))
# update previous_x
previous_x = x
return x_gd, y_gd
With gradient descent implemented, we'll will now run it.
x0 = 0.7
learning_rate = 0.15
epochs = 10
x = np.arange(-1, 5, 0.01)
y = func_y(x)
x_gd, y_gd = gradient_descent(x0, learning_rate, epochs)
Plot the animation.
from matplotlib import rc
from matplotlib.animation import FuncAnimation
from IPython.display import HTML
fig, ax = plt.subplots()
ax.set_xlim([min(x), max(x)])
ax.set_ylim([min(y)-1, max(y)+1])
ax.plot(x, y, lw = 0.9, color = 'k')
line, = ax.plot([], [], 'r', label = 'Gradient descent', lw = 1.5)
point, = ax.plot([], [], 'bo', animated=True)
value_display = ax.text(0.02, 0.02, '', transform=ax.transAxes)
def init():
"""Initializes the animation"""
line.set_data([], [])
point.set_data([], [])
value_display.set_text('')
return line, point, value_display
def animate(i):
"""Animates the plot at step i
Args:
i: the step to animate
return: a tuple of line, point, and value_display
"""
# Animate line
line.set_data(x_gd[:i], y_gd[:i])
# Animate points
point.set_data(x_gd[i], y_gd[i])
# Animate value display
value_display.set_text('Min = ' + str(y_gd[i]))
return line, point, value_display
# call the animator
rc('animation', html='html5')
anim = FuncAnimation(fig, animate, init_func=init,
frames=len(x_gd), interval=360,
repeat_delay=60, blit=True)
# display the video
HTML(anim.to_html5_video())
Exercises¶
- Try initializing x0 to something > 2, what do you observe?
- Try increasing the learning_rate to something large like 10. Does the gradient still converge?
- Replace func_y and gradient_func_y above with a cubic function. What do you observe?
y = x^3 - 5x^2 + x + 1 gradient(y) = 3x^2 - 10x + 1 - Replace func_y and gradient_func_y with
cos(x)and its derivative-sin(x). What do you observe? What needs to reach convergence?y = np.tan(x) gradient(y) = -np.sin(x)
Derivative formulas: https://www.derivative-calculator.net/
Gradient Descent Variants¶
- Stochastic Gradient Descent (SGD)
- Minibatch SGD
- Minibatch SGD with Momentum
- Adaptive Learning Rates
Stochastic Gradient Descent¶
"Regular" Gradient Descent is expensive because it processes all samples at once
- Imagine you have millions of training samples
Stochastic Gradient Descent speeds this up by:
- Running gradient descent, one randomly selected training sample at a time
- Stochastic: random noise, because samples can vary a lot
Notation¶
$\leftarrow$ = replace value Some texts use this symbol $:=$
Examples
- $\theta \leftarrow \theta - \epsilon g$
- $\theta := \theta - \epsilon g$
Means
- Compute $\theta' = \theta - \epsilon g$
- Update $\theta = \theta'$

Symbols:
- The $\eta_t$ denotes the learning rate
- Note: $\Theta$ is denotes the weights matrix
(image: Neural Networks in Natural Language Processing, Goldberg, 2017)
Minibatch Stochastic Gradient Descent¶
Instead of 1 random sample at a time:
- Sample a "minibatch" of m training samples
- Run gradient descent on that minibatch
- "Smooths" out the randomness by operating on a minibatch.
- The minibatch size can be tuned ("hyperparameter")

Symbols:
- $\epsilon_k$ denotes the learning rate
- $\theta$ denotes the weights matrix
- $\nabla_{\theta}$ means gradient w.r.t. $\theta$
(image: Deep Learning, Goodfellow, 2016)
Minibatch SGD, with momentum¶
Speeds up minibatch SGD by:
- Applying an exponentially decaying moving average of the previous gradients ($v$)
- if gradients point the same way, will reach minimum faster
- Minibatch SGD: $\theta \leftarrow \theta - \epsilon g$
- Minibatch SGD + momentum: $\theta \leftarrow \theta - \epsilon g + \alpha v$, $v \leftarrow v - \epsilon g$
Variant: Nesterov's momentum
Some intuition:
https://www.coursera.org/lecture/deep-neural-network/gradient-descent-with-momentum-y0m1f
Time position: 1:45

(image: Deep Learning, Goodfellow, 2016)
Adaptive Learning Rate Strategies¶
- Learning rate will control the amount of gradient update
- Large learning rate: risk overshoot and not converge
- Small learning rate: too slow
- Ideal: start large(r), then reduce as we get closer to minima
- Strategies
- Constant learning rate
- Time-based or step-based decay
- AdaGrad
- RMSProp
- Adam
- What works best depends on your domain (true for any optimization)

(image: machine learning mastery
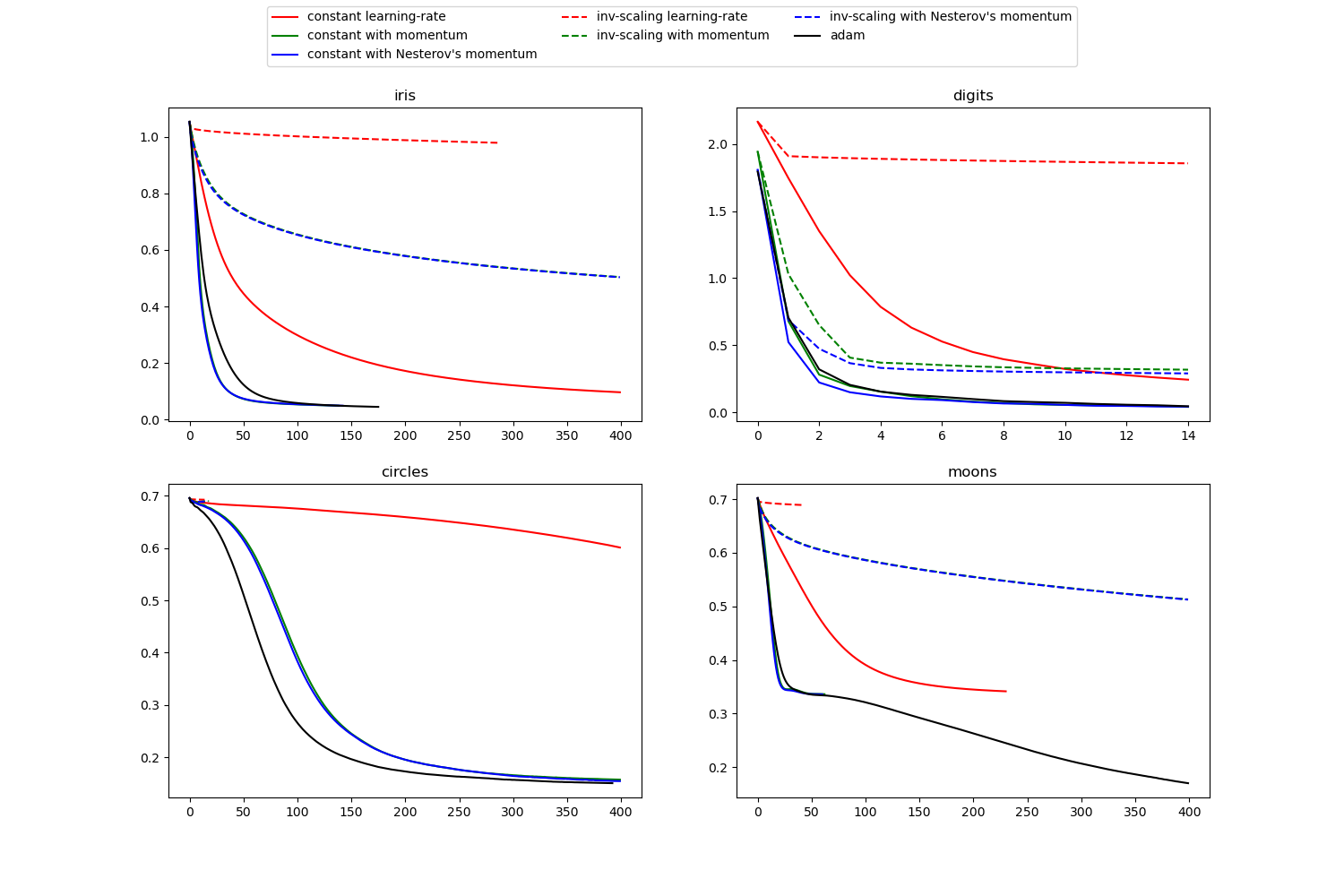
(image: scikit-learn)
Speed of Convergence¶
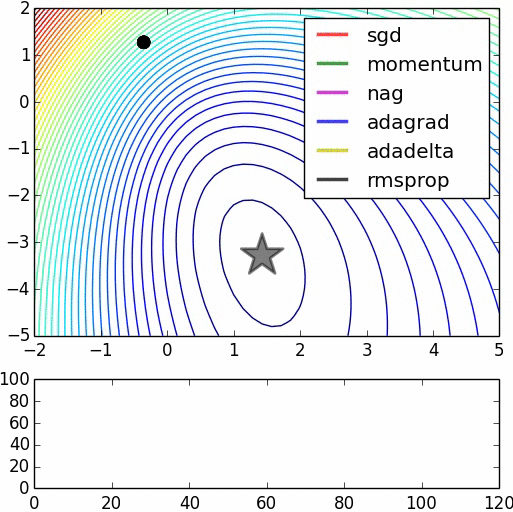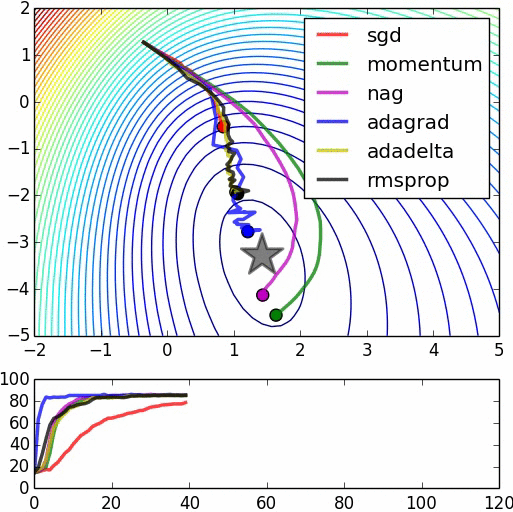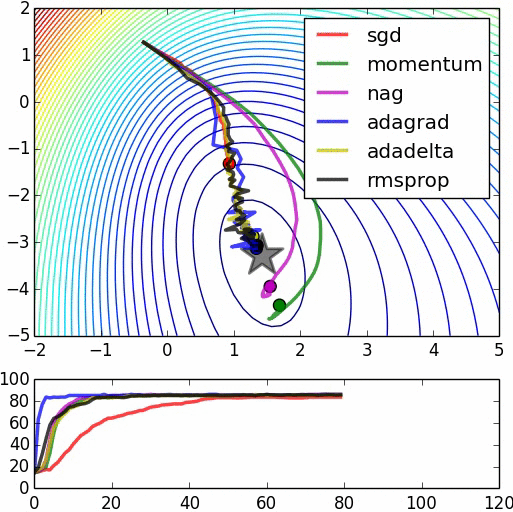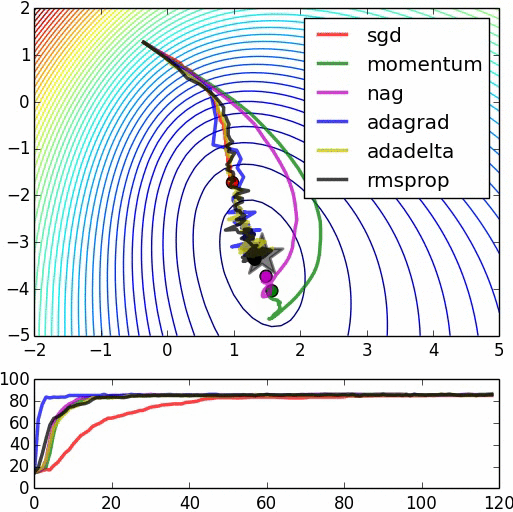
(image: https://leonardoaraujosantos.gitbooks.io/artificial-inteligence/content/model_optimization.html)
Underfiting, Overfitting¶
Goals of training¶
- Minimize training error
- Minimize gap between test error and training error. (the "generalization gap")
(Reference: Deep Learning - Goodfellow, Bengio, Courville, MIT press, 2016)
Generalization¶
How well will the model handle data not found during training?
Underfitting, Overfitting¶
- A model is set to "underfit" if the training error is too large
- A model is set to "overfit" if the gap between test and training error is too large
A good-fit model: neither underfit nor overfit (Goldilocks and the Three Bears)
Underfitting / High Bias¶
A model is set to "underfit" if the training error is too large
- Means model does not work
- It learnt nothing
- Mode has "high bias"
Overfitting / High Variance¶
A model is set to "overfit" if the gap between test and training error is too large
- Means model does not generalize well
- It only learnt the training set (or learnt too much training set noise)
- Model has "high variance"
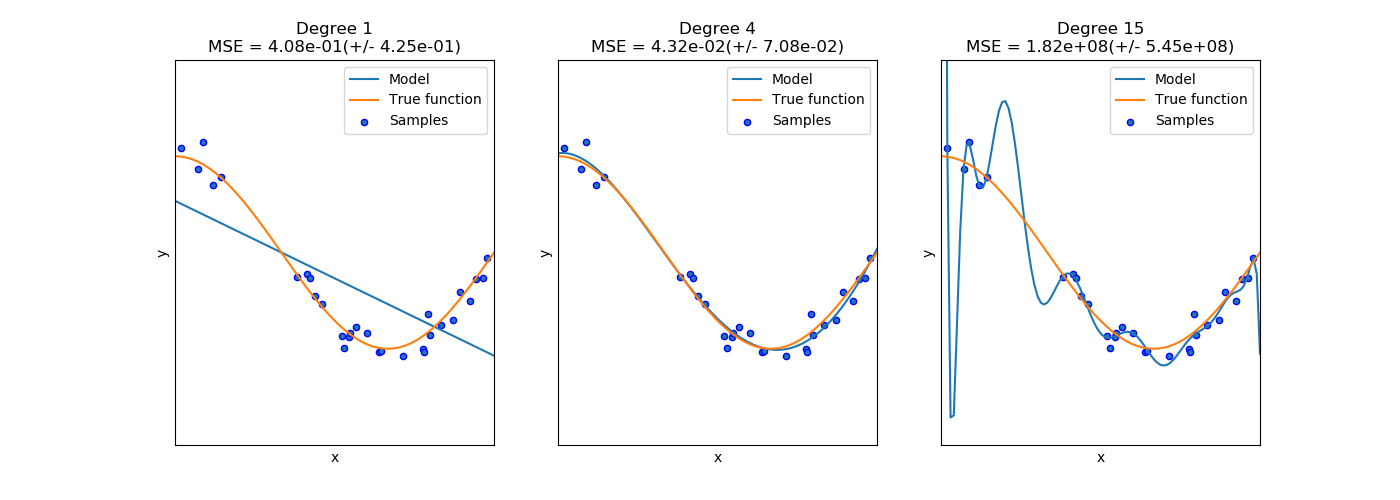
- Degree 1: Underfit / High Bias
- Degree 4: Good fit
- Degree 15: Overfit / High Variance
(image: http://scikit-learn.org/stable/auto_examples/model_selection/plot_underfitting_overfitting.html)
(image: xkcd)
Fixing Underfitting¶
Symptom: poor model performance even on training data
Potential cures:
- More data
- More features and/or different features
- Different algorithms
Fixing Overfitting¶
Symptom: model has good performance in training data, but poor generalization on test data
Potential cures:
- Early stoppping
- Fewer features
- Regularization
- Cross Validation
Workshop: SGD, Overfitting, Underfitting¶
In this workshop, we will try to fit a more complex linear regression model.
We'll explore the following concepts:
- Loss functions
- Stochastic Gradient Descent
- Underfitting and Overfitting
Inspiration: https://sdsawtelle.github.io/blog/output/week6-andrew-ng-machine-learning-with-python.html
Prediction Tasks¶
We'll try to fit a curve to predict, for recent Singapore University Graduates:
y: Gross Monthly Median Salary (S$)
x: Overall Employment Rate (%)To illustrate underfitting/overfitting, we'll explore:
- A first-order linear model: $y = w^Tx$
- A linear model with polynomial features $$y = w^TX$$ where $X = [1, x, x^2, x^3, ...]$
We'll also explore different loss functions and plotting of loss curves during training.
Dataset(s)¶
- Download this dataset: https://data.gov.sg/dataset/graduate-employment-survey-ntu-nus-sit-smu-sutd
- Unzip it and note the path for use in
pandas.read_csv
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
1. Data Transformation and Cleaning¶
The first step is to inspect the data to see what transformation/cleaning is needed.
# ISO-8859-1 encoding is needed
# UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe4 in position 20: invalid continuation byte
df = pd.read_csv('D:/tmp/graduate-employment-survey-ntu-nus-sit-smu-sutd/graduate-employment-survey-ntu-nus-sit-smu-sutd.csv',
encoding='ISO-8859-1',
usecols=['university', 'employment_rate_overall', 'gross_monthly_median'])
# filter by NUS to keep things simple
df = df.loc[df.university == 'National University of Singapore']
df.columns
The columns to inspect are:
- employment_rate_overall
- gross_monthly_median
We are looking for:
- invalid values
- data types to transform to numeric
- feature ranges
# the sample size is fairly small, we can inspect using .unique()
print(df.describe())
print('')
print(df.employment_rate_overall.unique())
employment_rate_overall column
- invalid values: yes, there is an 'na' value above
- data type is object (these are string values)
- need to transform to numbers
- How: use pandas.to_numeric to convert to numbers
- range: 0-100
If the dataset is large, it is hard to find the 'na' values.
A quick test is to try converting the column first, to see if errors appear.
pd.to_numeric(df.employment_rate_overall) # see if we get parse errors
We will be using the errors='coerce' option in pandas.to_numeric when we do the actual conversion.
pd.to_numeric(df.employment_rate_overall, errors='coerce') # 'na' becomes NaN
The gross_monthly_median column is handled the same way.
Let's now perform the data transformation and cleaning.
# transform string to numbers, forcing invalid values to float NaN
data = {
'gross_monthly_median': pd.to_numeric(df.gross_monthly_median, errors='coerce'),
'employment_rate_overall': pd.to_numeric(df.employment_rate_overall, errors='coerce')
}
# drop NaNs
df_dataset = pd.DataFrame(data).dropna()
df_dataset.head()
fig, ax = plt.subplots(figsize=(15, 8))
ax.scatter(df_dataset.employment_rate_overall, df_dataset.gross_monthly_median)
ax.set(title='Gross Monthly Median Income and Employment Rate for Recent NUS Graduates',
xlabel='Employment Rate (%)',
ylabel='Gross Monthly Median Income (S$)')
ax.grid()
Inspecting the plot above, we can roughly make out a curve through it.
2. Feature selection¶
Inputs¶
| Feature | Description | Column name | Transformation before model input? |
|---|---|---|---|
| $x_1$ | Overall Employment Rate (%) | employment_rate_overall | pd.to_numeric |
Outputs¶
| Output | Description | Truth column | Transformation from model output? |
|---|---|---|---|
| $\hat{y}$ | Predicted Gross Monthly Medium Income S\$ | $y$ = gross_monthly_median | None, output will stay numeric |
# Prepare the numpy arrays for use with sklearn
X = df_dataset.loc[:, 'employment_rate_overall']
print('X.shape:', X.shape)
y = df_dataset.loc[:, 'gross_monthly_median']
print('y.shape:', y.shape)
3. Model creation and training, and validation¶
In this section, we will
- Shuffle and then split dataset into train and test
- Perform feature scaling
- Train and validate our models
Dataset shuffling and train-test-split¶
In a previous workshop, we did the randomization and train-test split manually.
Turns out, sklearn.model_selection.train_test_split can do this for us.
from sklearn.model_selection import train_test_split
# train-test split, witholding 15% for test data
# shuffle=True is the default
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1)
X_train.head() # view the shuffled dataset
Feature scaling¶
Since we are using Stochastic Gradient Descent, we are recommended to scale the features between [0, 1] or [-1, 1].
Scaling subtracts the mean and divides by the standard deviation
- We will scale both the input and output values, using sklearn.preprocessing.StandardScaler
- In both cases (input and output), the mean and standard deviation will be based on the training set only. This way we don't look at the test set.
from sklearn.preprocessing import StandardScaler
# We train the scaler based on the training set, and use
# it for both the training and test sets
#
# Reason: the test set shouldn't pollute the dataset
x_scaler = StandardScaler()
x_scaler.fit(X_train.values.reshape(-1, 1)) # must be 2D array
X_train_scaled = x_scaler.transform(X_train.values.reshape(-1, 1))
X_test_scaled = x_scaler.transform(X_test.values.reshape(-1, 1))
y_scaler = StandardScaler()
y_scaler.fit(y_train.values.reshape(-1, 1))
y_train_scaled = y_scaler.transform(y_train.values.reshape(-1, 1))[:, 0]
y_test_scaled = y_scaler.transform(y_test.values.reshape(-1, 1))[:, 0]
X_train.head() # before scaling
X_train_scaled[:5] # after scaling (showing first 5 values)
y_train.head() # before scaling
y_train_scaled[:5] # after scaling (showing first 5 values)
Underfit Model: First Order Linear Regressor¶
For the first order linear regressor, we'll use sklearn.linear_model.SGDRegressor with the dataset above.
from sklearn.linear_model import SGDRegressor
# SGDRegressor?
linear_model = SGDRegressor(verbose=1,
random_state=np.random.RandomState(123),
loss='squared_loss', # mean squared loss
penalty='none', # no regularization
max_iter=100,
tol=1e-3, # stopping condition
eta0=0.01, # learning rate
learning_rate='constant') # learning rate schedule
%time linear_model.fit(X_train_scaled, y_train_scaled)
print('Coefficient', linear_model.coef_)
print('Intercept', linear_model.intercept_)
Model Validation¶
Let's validate our model's performance by computing metrics and plotting the linear model.
from sklearn.metrics import mean_squared_error, r2_score
pred_scaled = linear_model.predict(X_test_scaled)
print('Truth:', y_test_scaled)
print('Predictions:', pred_scaled)
# Compute metrics
print('MSE:', mean_squared_error(y_test_scaled, pred_scaled))
print('R2:', r2_score(y_test_scaled, pred_scaled))
Model Visualization¶
We'll visualize the entire dataset (train + test), by plotting the data as a sactter plot, and the linear function as a curve or line.
The model needs to be called with pre- and post-processing stages:
- Scale the input
- Call
predict - Unscale the output
In both steps, we'll use the already-fitted scalers from previously. This ensures that the pre- and post-processing matches exactly with how the model was trained.
# First, call the model in 3 stages
# 1. Pre-process the input
X_scaled = x_scaler.transform(X.values.reshape(-1, 1))
# 2. Predict
y_pred_scaled = linear_model.predict(X_scaled)
# 3. Post-process the output
y_pred = y_scaler.inverse_transform(y_pred_scaled)
# Finally, plot dataset and predictions
fig, ax = plt.subplots(figsize=(15, 8))
ax.scatter(X.values, y, label='truth')
ax.plot(X.values, y_pred, label='predictions', color='orange')
ax.set(title='Gross Monthly Median Income and Employment Rate for Recent NUS Grads: First-Order Model',
xlabel='Employment Rate (%)',
ylabel='Gross Monthly Median Income (S$)')
ax.grid()
ax.legend()
Polynomial Regression¶
A linear model is obviously underfit, because it tries to draw a straight line. Let's try a curve instead (polynomial model).
To generate polynomial features from x (Employment Rate), we use sklearn.preprocessing.PolynomialFeatures
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(12)
poly.fit(X_train.values.reshape(-1, 1))
X_train_poly = poly.transform(X_train.values.reshape(-1, 1))
X_test_poly = poly.transform(X_test.values.reshape(-1, 1))
# Scale the features back to SGD happy ranges ([-1, 1])
x_scaler_poly = StandardScaler()
x_scaler_poly.fit(X_train_poly)
X_train_poly_scaled = x_scaler_poly.transform(X_train_poly)
X_test_poly_scaled = x_scaler_poly.transform(X_test_poly)
poly_model = SGDRegressor(verbose=1,
random_state=np.random.RandomState(123),
loss='squared_loss', # mean squared loss
penalty='none', # no regularization
max_iter=100,
tol=1e-4, # stopping condition
eta0=0.01, # learning rate
learning_rate='constant') # learning rate schedule
%time poly_model.fit(X_train_poly_scaled, y_train_scaled)
print('Coefficients', poly_model.coef_)
print('Intercept', poly_model.intercept_)
Exercise: Model Validation and Visualization¶
Follow the pattern above to validate and visualize the new model.
This means two tasks:
- Computing metrics
- Plotting the curve (hint: use a scatter plot for both)
If you prefer to plot a line for the predictions, you can create a sorted DataFrame:
df_plot = pd.DataFrame({'y_pred': y_pred}, index=X.values)
df_plot.sort_index(inplace=True)
df_plot.plot(ax=ax, label='predictions', color='orange')# Compute metrics
# Your code here
# Plot curve
# First, call the model in 3 stages
# 1. Pre-process the input
# Hint: you need to create the polynomial, then scale
#
# Your code here
# 2. Predict
#
# Your code here
# 3. Post-process the output by un-scaling y
#
# Your code here
# Finally, plot dataset and predictions
#
# Your code here
Learning Curves for Underfit/Overfit Detection¶
Even with the above polynomial curve, it's hard to tell if we are truly overfitting.
The standard practice to determine model fit is to plot learning curves of the training scores and test scores during training iterations.
Let's compare the learning curves for both the linear and polynomial case.
Reference: http://scikit-learn.org/stable/auto_examples/model_selection/plot_learning_curve.html
from sklearn.model_selection import learning_curve
# learning_curve?
def plot_learning_curve(axis, title, tr_sizes, tr_scores, val_scores):
"""Plots the learning curve for a training session
Arg:
axis: axis to plot
title: plot title
tr_sizes: sizes of the training set
tr_scores: training scores
val_scores: validation scores
"""
tr_scores_mean = np.mean(tr_scores, axis=1)
tr_scores_std = np.std(tr_scores, axis=1)
val_scores_mean = np.mean(val_scores, axis=1)
val_scores_std = np.std(val_scores, axis=1)
axis.fill_between(tr_sizes, tr_scores_mean - tr_scores_std,
tr_scores_mean + tr_scores_std, alpha=0.1,
color="r")
axis.fill_between(tr_sizes, val_scores_mean - val_scores_std,
val_scores_mean + val_scores_std, alpha=0.1, color="g")
axis.plot(tr_sizes, tr_scores_mean, 'o-', color="r",
label="Training score")
axis.plot(tr_sizes, val_scores_mean, 'o-', color="g",
label="Cross-validation score")
axis.set(title=title,
xlabel='Training examples',
ylabel='R2 Scores')
axis.grid()
axis.legend()
# Generate the learning curve for linear_model
# By default this uses 3-fold Cross Validation (more on that later)
train_sizes, train_scores, validation_scores = learning_curve(
linear_model, X_train_scaled, y_train_scaled,
random_state=np.random.RandomState(123))
# Plot the learning curve, along with the stats
fig, ax = plt.subplots(figsize=(15, 8))
plot_learning_curve(ax, '1st Order Model',
train_sizes, train_scores, validation_scores)
Exercise: Plot Learning Curve¶
Follow the example above and:
- Generate the learning curve for the polynomial model (
poly_model) - Plot the learning curve and the statistics
# 1. Generate the learning curve for poly_model
#
# Your code here
# 2. Plot the learning curve, along with the stats
#
# Your code here
Observations¶
The learning curves show:
- Both models are underfit: the training scores are very low.
- Why? The data is quite dispersed, and linear regression is probably not a good way to model this
- The polynomial model generalizes slightly better
- It has a narrower gap between training scores and validation scores
Robust Linear Regression against Outliers¶
The most obvious problem with the data is the presence of lots of outliers.
There are some models that are a bit more robust against outliers. One of them is the RANdom SAmple Consensus model (RANSAC), which can be trained using a baseline estimator to split the data into two sets: inliers and outliers.
http://scikit-learn.org/stable/modules/linear_model.html#ransac-random-sample-consensus
Let's give it a try.
from sklearn.linear_model import RANSACRegressor
ransac = RANSACRegressor(poly_model,
random_state=np.random.RandomState(123))
%time ransac.fit(X_train_poly_scaled, y_train_scaled)
pred_scaled = ransac.predict(X_test_poly_scaled)
print('Truth:', y_test_scaled)
print('Predictions:', pred_scaled)
# Compute metrics
print('MSE:', mean_squared_error(y_test_scaled, pred_scaled))
print('R2:', r2_score(y_test_scaled, pred_scaled))
inlier_mask = ransac.inlier_mask_
outlier_mask = np.logical_not(inlier_mask)
X_poly = poly.transform(X.values.reshape(-1, 1))
X_poly_scaled = x_scaler_poly.transform(X_poly)
y_pred_scaled = ransac.predict(X_poly_scaled)
y_pred = y_scaler.inverse_transform(y_pred_scaled)
fig, ax = plt.subplots(figsize=(15, 8))
ax.scatter(X_train[inlier_mask], y_train[inlier_mask],
color='cornflowerblue', marker='o', label='inliers')
ax.scatter(X_train[outlier_mask], y_train[outlier_mask],
color='red', marker='x', label='outliers')
ax.scatter(X.values, y_pred,
color='orange', label='predictions')
ax.set(title='Gross Monthly Median Income and Employment Rate: RANSAC with 12th Degree Baseline',
xlabel='Employment Rate (%)',
ylabel='Gross Monthly Median Income (S$)')
ax.grid()
ax.legend()
train_sizes, train_scores, validation_scores = learning_curve(
ransac, X_train_poly_scaled, y_train_scaled,
train_sizes=[0.25, 0.5, 0.75, 1],
random_state=np.random.RandomState(123))
fig, ax = plt.subplots(figsize=(15, 8))
plot_learning_curve(ax, 'RANSAC Model',
train_sizes, train_scores, validation_scores)
Cross Validation¶
Cross validation was used when plotting the learning curves. Here's what K-fold Cross Validation does:
- Partition training samples into K equal-sized groups
- Pick a group for each training iteration:
- train with the remaining K-1 groups
- validate with this group
 (image: wikipedia)
(image: wikipedia)
Benefits:
- Better measure of generalization than sticking to the same training set
- Helps smaller datasets train better by varying training set
More explanation: http://scikit-learn.org/stable/modules/cross_validation.html
Regularization¶
Regularization is applied when there is overfitting.
- It's a heuristic.
- Adds a large constant value $\lambda$ * some aggregate of weights
- Penalizes the weights, so that they won't fit as well to training data as models get more complicated
L1 regularization:
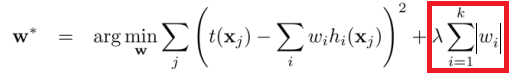
L2 regularization:
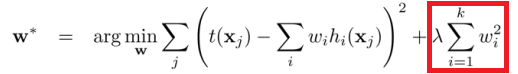
(images: chioka.in)
To illustrate this, let's try adding regularization to the Polynomial Model.
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(20, 10))
print('Regularization parameter: 100')
poly_model = SGDRegressor(penalty='l1',
alpha=100,
tol=1e-4,
max_iter=1000,
random_state=np.random.RandomState(123))
poly_model.fit(X_train_poly_scaled, y_train_scaled)
print('Coefficients', poly_model.coef_)
print('Intercept', poly_model.intercept_)
train_sizes, train_scores, validation_scores = learning_curve(
poly_model, X_train_poly_scaled, y_train_scaled,
random_state=np.random.RandomState(123))
plot_learning_curve(ax[0], 'Regularization Type: L1 (alpha = 100)',
train_sizes, train_scores, validation_scores)
print('Regularization parameter: 0.05')
poly_model = SGDRegressor(penalty='l1',
alpha=0.05,
tol=1e-4,
max_iter=1000,
random_state=np.random.RandomState(123))
poly_model.fit(X_train_poly_scaled, y_train_scaled)
print('Coefficients', poly_model.coef_)
print('Intercept', poly_model.intercept_)
train_sizes, train_scores, validation_scores = learning_curve(
poly_model, X_train_poly_scaled, y_train_scaled,
random_state=np.random.RandomState(123))
plot_learning_curve(ax[1], 'Regularization Type: L1 (alpha = 0.05)',
train_sizes, train_scores, validation_scores)
Exercise: Multi-Variate Regression with UCI dataset¶
Since the previous exercise was unsatisfactory (in terms of our results), let's run through the steps with a (hopefully better) dataset available in the UCI repository.
https://archive.ics.uci.edu/ml/datasets/Concrete+Compressive+Strength
This is also a good opportunity to review what we have learnt so far.
You'll practice doing these tasks:
- Explore Data
- Data Processing & Feature Selection
- Training an initial model using Linear Regression with SGD
- You should use learning_curve() which will give you a learning curve in parallel with training
- Get evaluation metrics
- Explore improving the initial model (choose your own adventure)
Download dataset¶
- Go to https://archive.ics.uci.edu/ml/datasets/Concrete+Compressive+Strength
- Download the dataset into a folder
The dataset includes:
- Concrete_Data.xls: an Excel spreadsheet of the data
- Concrete_Readme.txt: description of the dataset columns and output variable
Explore data¶
Use pandas.read_excel to read Concrete_Data.xls
https://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_excel.html
pandas.read_excel needs the following library installed:
(mldds02) conda install xlrd# Read the data from Concrete_Data.xls using pd.read_excel
# The default options should be okay, but you can be adventurous
# Explore the data by using describe(), checking that values
#
# Your code here
Visualization¶
We can't plot all the columns at the same time, but we can use PCA to reduce the X dimensions to 2 and then make a 3D plot with y.
http://scikit-learn.org/dev/modules/generated/sklearn.decomposition.PCA.html
# Plotting the data
# Reference: http://scikit-learn.org/dev/auto_examples/decomposition/plot_pca_iris.html
# interactive plot
%matplotlib notebook
from sklearn import decomposition
from mpl_toolkits.mplot3d import Axes3D
np.random.seed(123)
X = df.iloc[:, :8] # Features
y = df.iloc[:, 8] # Concrete compressive strength(MPa, megapascals)
fig = plt.figure(1, figsize=(8, 6))
plt.clf()
ax = Axes3D(fig, rect=[0, 0, .95, 1], elev=48, azim=134)
pca = decomposition.PCA(n_components=2)
X = pca.fit_transform(X.values)
ax.scatter(X[:,0], X[:, 1], y, edgecolor='k')
ax.set_xlabel('X1')
ax.set_ylabel('X2')
ax.set_zlabel('y')
Select your features based on the description in Concrete_Readme.txt.
Here's a snippet of the important section, but you should also read through the whole file.
Variable Information:
Given is the variable name, variable type, the measurement unit and a brief description.
The concrete compressive strength is the regression problem. The order of this listing
corresponds to the order of numerals along the rows of the database.
Name -- Data Type -- Measurement -- Description
Cement (component 1) -- quantitative -- kg in a m3 mixture -- Input Variable
Blast Furnace Slag (component 2) -- quantitative -- kg in a m3 mixture -- Input Variable
Fly Ash (component 3) -- quantitative -- kg in a m3 mixture -- Input Variable
Water (component 4) -- quantitative -- kg in a m3 mixture -- Input Variable
Superplasticizer (component 5) -- quantitative -- kg in a m3 mixture -- Input Variable
Coarse Aggregate (component 6) -- quantitative -- kg in a m3 mixture -- Input Variable
Fine Aggregate (component 7) -- quantitative -- kg in a m3 mixture -- Input Variable
Age -- quantitative -- Day (1~365) -- Input Variable
Concrete compressive strength -- quantitative -- MPa -- Output Variable# Select your features based on the Variable Information from Concrete_Readme.txt
#
# This (usually) means:
# 1. Splitting the DataFrame into X and y, by selecting the appropriate columns
# iloc is easier if you didn't set column names (because the
# column names have spaces in them)
# 2. Do a train/test split with shuffle
# 3. Scale X_train, X_test, y_train, y_test
#
# Your code here
# Select X and y (already done above in the plotting code)
# Train/Test split into X_train, X_test, y_train, y_test
# Scale X_train, X_test, y_train, y_test
As an initial model, we'll train a Linear Regressor using SGD to see what we get.
# Train a linear regression using SGD
# Use learning_curve() so that you can check the goodness-of-fit
# Plot the learning curve
#
# Your code here
# Reset the interactive mode
%matplotlib inline
Compute metrics on the test set:
- Call model.fit
- Call model.predict to get the scaled predictions (y_pred_scaled)
- Get the mean_squared_error and r2_score using y_test_scaled and y_pred_scaled
# Your code here
# Call model.fit
# Call model.predict to get the scaled predictions (y_pred_scaled)
# Get the mean_squared_error and r2_score using y_test_scaled and y_pred_scaled
Explore improving the baseline model (choose your own adventure)
- Trying different learning rate schedules
- Trying different regularization settings in SGDRegressor
- Trying GridSearchCV to perform hyperparameter searches http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html
- Trying Polynomial features
- Trying other regressors. For example:
# Try improving upon the baseline model, by selecting one or more
# of the options above.
#
# Your code here
Reading List¶
| Material | Read it for | URL |
|---|---|---|
| Optimization - Artificial Intelligence | Overview of Gradient Descent | https://leonardoaraujosantos.gitbooks.io/artificial-inteligence/content/model_optimization.html |
| Chapter 5, Pages 107-119 | Capacity, Overfitting and Underfitting | http://www.deeplearningbook.org/contents/ml.html |
| Machine Learning Explained: Regularization | Graphical comparison of different types of Regularization | http://enhancedatascience.com/2017/07/04/machine-learning-explained-regularization/ |