
Topics¶
- Decision Trees
- Ensemble Forests
- Classification
- Regression
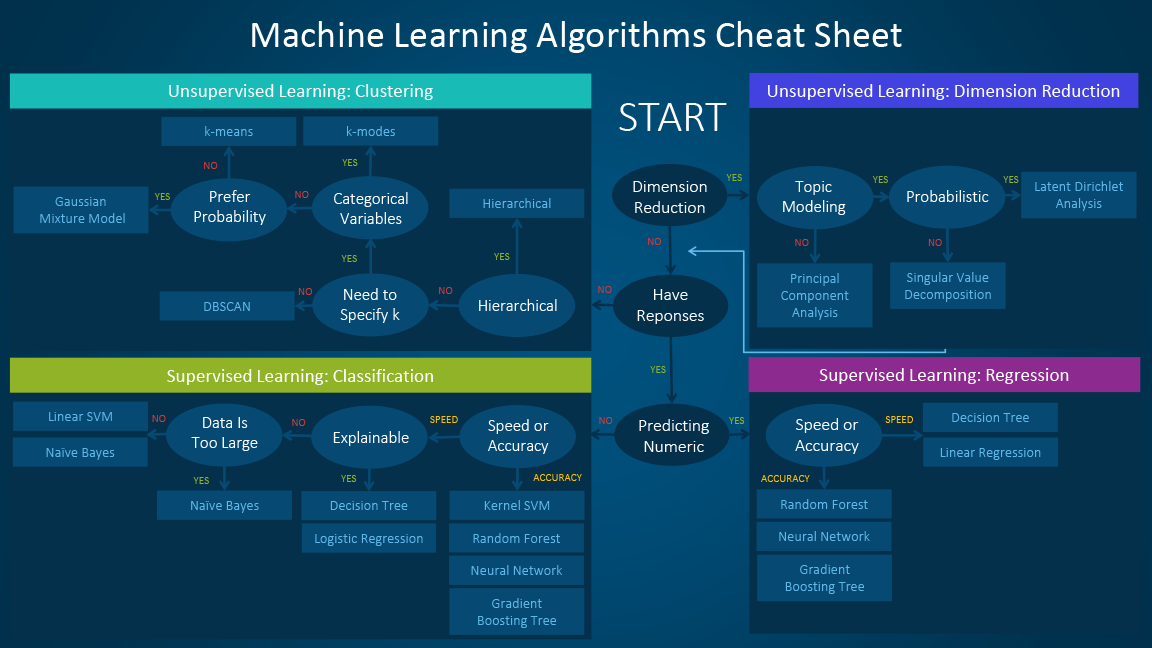
Decision Trees¶
- Classification: predicts a class
- Regression: predicts a number
Decision Trees¶
Advantanges:
- Easy to visualize and understand
- $O(log(N))$ prediction cost
- Flexible for simple tasks: binary / multi-class classification, regression
Decision Trees¶
Disadvantages:
- Overfitting
- Unbalanced dataset can cause biased trees
- Instability: small changes in data can result in completely different tree

Ensemble Methods¶
"Teaming up weaker models to create a stronger model"
- Random Forest
- AdaBoost
- Gradient Boosted Trees
- etc
Random Forests¶
- Fits a few decision trees on subsets of the dataset, then averages the results
- Improves accuracy and reduces overfitting
- Classifier: http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
- Regressor: http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestRegressor.html
AdaBoost¶
- http://scikit-learn.org/stable/modules/ensemble.html#adaboost
Fit a sequence of small decision trees on repeatedly modified versions of data
- adjust weights on the training samples
- incorrectly predicted training sample => more weight
- correctly predicted sample => less weight
- adjust weights on the training samples
Combine predictions using sum or majority vote
"Samples that were gotten wrong get more attention"
Gradient Boosted Trees¶
- Optimized using Gradient Descent
- Better generalization
- Classifier: http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingClassifier.html
- Regressor: http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingRegressor.html
Gradient Boosting¶

(image: http://blog.kaggle.com/2017/01/23/a-kaggle-master-explains-gradient-boosting/)
Gradient Boosting: Concept¶
Nth tree has some prediction error.
Train the next (N+1)th tree to "boost" the model so that it can compensate for the gap (error) from the Nth tree.
Add up the predictions from the all trees to fill up the gaps.
Gradient Boosting: Concept¶
- Train first tree, measure training error ("residuals") $$F_1(x) = y$$
- Train second tree on the residuals, using dataset $\big(x, y-F_1(x)\big)$ $$h_1(x) = y - F_1(x)$$
- Combine to get a better model $$F_2(x) = F_1(x) + h_1(x)$$
Gradient Boosting: Concept¶
General formulation: $$F_{m+1}(x) = F_m(x) + h_m(x) = y$$
Where $m$ is tuned by cross validation
Gradient Boosting: Gradient Descent¶
- Objective: minimize cost function: $L\big(y, F(x)\big)$
- Apply Tree Boosting, but compute residuals from the gradients of the cost function
- $n$ training examples $(x_1, ... x_n)$
- Residual for the $i^{th}$ example, $m^{th}$ tree:
$$r_{im} = -\biggl[\frac{\partial{L\big(y_i, F_{m-1}(x_i)\big)}}{\partial{F_{m-1}(x_i)}}\biggr]$$
Gradient Boosting: Algorithm¶
- Compute residual using $F_{m-1}(x_i)$ and $y_i$
- Train decision tree $h_m(x)$, using dataset ${(x_i, r_{im})}$
- Compute update multiplier: $$\gamma_m = \underset{\gamma}{\arg \min} \sum^n_{i=1} L\big(y, F_{m-1} + \gamma h_{m}(x)\big)$$
- Get next model using multiplier: $$F_m(x) = F_{m-1}(x) + \gamma_mh_m(x)$$
XGBoost¶
eXtreme Gradient Boosting
- A parallel, distributed gradient boosting library
- https://github.com/dmlc/xgboost
- https://xgboost.readthedocs.io/en/latest/model.html
Evaluation Metrics¶
- General metrics for Classification and Regression
- Decision Tree-specific metrics
Decision Tree-specific Metrics¶
- Gini: gini impurity, which measures the quality of a split
- greater than 0: split needed
- 0: all cases fall in 1 category
- Information gain / entropy
- pick the split with the highest information gain
Workshop: Classification with Decision Trees¶
Credits: http://scikit-learn.org/stable/modules/tree.html#classification
Setup¶
We'll be using Graphviz to visualize the decision tree after training it.
Add this module to your mldds02 conda environment:
conda install python-graphvizGoal¶
Train and compare decision tree-based classifiers to predict the sector from research and development expenditure type, cost type, and expenditure amount.
Dataset¶
Research and Development Expenditure by Type of Cost¶
https://data.gov.sg/dataset/research-and-development-expenditure-by-type-of-cost
- Download dataset from the above URL
- Extract the folder and note the path for use in
read_csvbelow.
Prepare Dataset¶
- Encode string labels to numbers
- Ensure dataset is balanced
import pandas as pd
df = pd.read_csv('../data/research-and-development-expenditure-by-type-of-cost/research-and-development-expenditure-by-type-of-cost.csv',
usecols=['sector', 'type_of_expenditure', 'type_of_cost', 'rnd_expenditure'])
df.head()
Label Encoding for Classification¶
Training data needs to be numeric.
To convert string labels to numbers, we will do something called "label encoding".
There are multiple ways to do this: http://pbpython.com/categorical-encoding.html
- Dummy columns
- Integer labels
For this dataset, we'll try assigning integer labels to each unique string value in the column.
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
# encode sector from strings to integer labels
df['sector_c'] = le.fit_transform(df['sector'])
df['type_of_expenditure_c'] = le.fit_transform(df['type_of_expenditure'])
df['type_of_cost_c'] = le.fit_transform(df['type_of_cost'])
df.head(10)
Ensuring Balanced Dataset for Decision Tree Algorithms¶
For decision trees, it is important to balance the dataset to reduce class bias.
If a dataset contains too many samples of one sector (e.g. 'Private Sector', the tree will learn to pick that sector more frequently, which means it's no better than random selection.
# Detect if a dataset is unbalanced
df['sector_c'].value_counts()
We got lucky here with the dataset, as there are equal numbers of value_counts for each sector.
Suppose we need to balance the dataset, we can use this technique:
# simulate an unbalanced dataset by replicating columns for sector_c=0
df.loc[df.sector_c == 0]
# make a copy so as not to affect our original df
unbalanced_df = pd.concat([df, df.loc[df.sector_c == 0]], ignore_index=True)
# show the unbalanced dataset, sector_c = 0 will have double the number of entries
unbalanced_df['sector_c'].value_counts()
sector_groups = unbalanced_df.groupby('sector_c')
# use pandas.DataFrame.sample to create a DataFrame
# where all sector groups are re-sampled to the smallest sized group
balanced_df = sector_groups.apply(lambda x: x.sample(sector_groups.size().min())).\
reset_index(drop=True)
# show the balanced_df, all sectors are balanced
balanced_df['sector_c'].value_counts()
Select Features¶
We'll now break our DataFrame into data and target.
data = df[['rnd_expenditure', 'type_of_expenditure_c', 'type_of_cost_c']]
target = df['sector_c']
data.head()
target.head()
Train the Decision Tree Classifier¶
- Shuffle and split the data set into train and test
- Train a
DecisionTreeClassifier
http://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html
from sklearn.model_selection import train_test_split
train_X, test_X, train_y, test_y = train_test_split(data, target)
from sklearn.tree import DecisionTreeClassifier
dtc = DecisionTreeClassifier()
dtc.fit(train_X, train_y)
dtc.predict(test_X)
# Probabilities are expressed as a
# fraction of samples of the same class in a leaf
dtc.predict_proba(test_X)
Evaluate Metrics: Classification Accuracy¶
Since this is a classification task, the metrics we used for Logistic Regression also apply here, such as
- Precision, recall
- Confusion matrix
- Accuracy
References:
from sklearn.metrics import classification_report, confusion_matrix
pred_y = dtc.predict(test_X)
print(classification_report(test_y, pred_y))
cm = confusion_matrix(test_y, pred_y)
print(cm)
Visualizing the Decision Tree¶
We'll visualize the learned decision tree using graphviz, to see what type of rules it has learnt from the training data.
from sklearn.tree import export_graphviz
import graphviz
def visualize_tree(fitted_tree, feature_names, target_names, filename):
"""
Args:
fitted_tree: the fitted decision tree. If using ensemble methods
pick the first estimator using model.estimators[0]
feature_names: array containing the feature names
target_names: array containing the target labels
filename: the filename to save the .dot file
"""
export_graphviz(fitted_tree, out_file=filename,
feature_names=feature_names,
class_names=target_names,
filled=True, rounded=True)
source = graphviz.Source.from_file(filename)
source.render(view=True)
feature_names=['rnd_expenditure', 'type_of_expenditure', 'type_of_cost']
target_names=df['sector'].unique()
filename = '../data/govt_sector_by_expenditure_tree.dot'
visualize_tree(dtc, feature_names, target_names, filename)
Exercise - Decision Tree Classification using Entropy¶
Repeat the steps above to:
- Train a decision tree using the 'entropy' criteria using the training set
- Evaluate the classification metrics
- Visualize the decision tree
Which criteria performs better?
# Your code here
Visualizing Decision Tree Surfaces¶
Here's a neat trick to try in lieu of what we saw with clustering.
Credits: http://scikit-learn.org/stable/auto_examples/tree/plot_iris.html
# Adapted from: http://scikit-learn.org/stable/auto_examples/tree/plot_iris.html
import numpy as np
def plot_decision_surface(classifier, n_classes, X, y, title):
"""Plots a decision surface using pair-wise combination
of features
Args:
classifier - the decision tree classifier
n_classes - the number of classes
X - the data
y - the labels
title - the plot title
"""
plot_colors = 'ryb'
plot_step = 0.02
plt.figure(figsize=(15, 10))
for pairidx, pair in enumerate([[0, 1], [0, 2], [1, 2]]):
# We only take the two corresponding features
x = X.values[:, pair]
clf = classifier.fit(x, y)
# Plot the decision boundary
plt.subplot(2, 3, pairidx + 1)
x_min, x_max = x[:, 0].min() - 1, x[:, 0].max() + 1
y_min, y_max = x[:, 1].min() - 1, x[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, plot_step),
np.arange(y_min, y_max, plot_step))
plt.tight_layout(h_pad=0.5, w_pad=0.5, pad=2.5)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
cs = plt.contourf(xx, yy, Z, cmap=plt.cm.RdYlBu)
plt.xlabel(feature_names[pair[0]])
plt.ylabel(feature_names[pair[1]])
# Plot the training points
for i, color in zip(range(n_classes), plot_colors):
idx = np.where(y == i)
plt.scatter(x[idx, 0], x[idx, 1], c=color, label=target_names[i],
cmap=plt.cm.RdYlBu, edgecolor='black', s=15)
plt.suptitle(title)
plt.legend(loc='lower right', borderpad=0, handletextpad=0)
plt.axis("tight")
plt.show()
n_classes = len(target.unique())
plot_decision_surface(DecisionTreeClassifier(), n_classes, train_X, train_y,
"Decision surface of a Decision Tree classifier using paired features")
# To get the category label mapping
df[['type_of_expenditure', 'type_of_expenditure_c']].drop_duplicates()
df[['type_of_cost', 'type_of_cost_c']].drop_duplicates()
df[['sector', 'sector_c']].drop_duplicates()
Random Forest Classifier with GridSearchCV¶
Now that we have our baseline tree, the next step is to try an ensemble method, such as Random Forest.
Let's also maximize our chances of getting the best model by doing Grid Search cross-validation.
http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html
from sklearn.ensemble import RandomForestClassifier
RandomForestClassifier?
from sklearn.model_selection import GridSearchCV
# Use GridSearchCV to select the optimum hyperparameters
gs_rfc = GridSearchCV(RandomForestClassifier(), {'max_depth': [2, 4, 6, 8],
'n_estimators': [5, 10, 20, 30]},
verbose=1)
gs_rfc.fit(train_X, train_y)
# select the best estimator
print('Best score:', gs_rfc.best_score_)
print('Best parameters:', gs_rfc.best_params_)
# predict
pred_y = gs_rfc.predict(test_X)
# evaluation metrics
print(classification_report(test_y, pred_y))
cm = confusion_matrix(test_y, pred_y)
print(cm)
gs_rfc.best_estimator_
gs_rfc.best_estimator_.estimators_
# Visualize the first tree in the forest
rfc = gs_rfc.best_estimator_
visualize_tree(rfc.estimators_[0], feature_names, target_names,
'../data/research-and-development-expenditure-by-type-of-cost/govt_sector_by_expenditure_rf_first.dot')
# Visualize the last tree in the forest
visualize_tree(rfc.estimators_[-1], feature_names, target_names,
'../data/research-and-development-expenditure-by-type-of-cost/govt_sector_by_expenditure_rf_last.dot')
# Plot the decision surface for pair-wise features, using
# the best estimator found by GridSearchCV
best_n_estimators = n_estimators=gs_rfc.best_params_['n_estimators']
best_max_depth = n_estimators=gs_rfc.best_params_['max_depth']
plot_decision_surface(RandomForestClassifier(n_estimators=best_n_estimators,
max_depth=best_max_depth),
n_classes, train_X, train_y,
"Decision surface of a Random Forest classifier using paired features")
XGBoost Classifier with GridSearchCV¶
Finally, let's try XGBoost on our dataset, to see how well it does.
Setup¶
XGBoost is a separate library from sklearn (https://xgboost.readthedocs.io/en/latest/build.html)
conda install -c anaconda py-xgboostXGBoost and Scikit-learn¶
XGBoost has its own API, but includes an sklearn wrapper for convenience.
https://github.com/dmlc/xgboost/blob/master/demo/guide-python/sklearn_examples.py
import xgboost as xgb
# Use GridSearchCV to select the optimum hyperparameters
gs_xgb = GridSearchCV(xgb.XGBClassifier(), {'max_depth': [2, 4, 6, 8],
'n_estimators': [5, 10, 20, 30]},
verbose=1)
gs_xgb.fit(train_X, train_y)
# select the best estimator
print('Best score:', gs_xgb.best_score_)
print('Best parameters:', gs_xgb.best_params_)
# predict
pred_y = gs_xgb.predict(test_X)
# evaluation metrics
print(classification_report(test_y, pred_y))
cm = confusion_matrix(test_y, pred_y)
print(cm)
Workshop: Regression with Decision Trees¶
In this workshop, we will apply decision tree-related algorithms to a multi-variate linear regression problem.
Goal¶
Train a regression model to predict the Lifetime Post Total Reach of a Facebook post to seven input features (category, page total likes, type, month, hour, weekday, paid).
Dataset¶
Facebook metrics Data Set¶
https://archive.ics.uci.edu/ml/datasets/Facebook+metrics
The data is related to posts' published during the year of 2014 on the Facebook's page of a renowned cosmetics brand.
- Download dataset from the above URL
- Extract the folder and note the path for use in read_csv below.
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('../data/Facebook_metrics/dataset_Facebook.csv',
delimiter=';',
usecols=['Page total likes', 'Type', 'Category',
'Post Month', 'Post Weekday', 'Post Hour', 'Paid',
'Lifetime Post Total Reach'])
df.head()
Prepare Dataset¶
Handle NaN values¶
Check for NaN values and decide what to do with them.
Convert string columns¶
There are two options for the Type column.
- Convert to dummy columns.
- Encode the labels to numbers.
Either option is fine because the number of labels is small (4). Since we've demonstrated label encoding, we'll try the dummy column approach.
Balance dataset¶
This is a regression task, so we don't need to balance the Lifetime Post Total Reach output, because it is a continuous variable.
- Instead, we'll check that the discrete columns (
Type,Category,Paid) values are balanced. - It's less critical, but a good idea to also check the
Post Month,Post WeekdayandPost Hourcolumns, just in case.
Handle NaN values¶
Check for NaN values and decide what to do with them.
df.info()
df[df.isnull().any(axis=1)]
df.dropna(inplace=True)
Convert string columns¶
Convert Type to dummy columns and append to DataFrame
df_type_dummies = pd.get_dummies(df['Type'])
df_type_dummies.head()
# Append to existing dataset
df = pd.concat([df, df_type_dummies], axis=1)
df.head()
Balance dataset¶
Check that these discrete columns are balanced
TypeCategoryPaid
Optionally, check that these discrete columns are balanced
Post MonthPost WeekdayPost Hour
Balanced means that the counts for each discrete values are not overly biased to one or two values. As a rule of thumb, overly means 10x or larger.
# Detect if the `Type` column is balanced
df['Type'].value_counts()
# Instead of dropping all the columns, let's reduce just the `Photo` rows by a random sample of 90 entries
num_photo_rows = 90
photos_df = df.loc[df.Type == 'Photo']
indices_to_keep = photos_df.sample(num_photo_rows).index # random sample the indices
indices_to_drop = list(set(photos_df.index) - set(indices_to_keep))
balanced_df = df.drop(df.index[indices_to_drop])
balanced_df['Type'].value_counts()
balanced_df['Category'].value_counts()
balanced_df['Paid'].value_counts()
balanced_df.info()
# Label Encode
type_le = LabelEncoder()
balanced_df.Type = type_le.fit_transform(balanced_df.Type)
Select Features¶
Select the features X and y from balanced_df.
X = balanced_df.loc[:, balanced_df.columns != 'Lifetime Post Total Reach']
y = balanced_df['Lifetime Post Total Reach']
print(X.shape, y.shape)
Train the Decision Tree Regressor¶
- Shuffle and split the data set into train and test
- Train a
DecisionTreeRegressor
http://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeRegressor.html
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error, r2_score
train_X, test_X, train_y, test_y = train_test_split(X, y, random_state=42)
X_scaler = StandardScaler()
train_X_scaled = X_scaler.fit_transform(train_X)
test_X_scaled = X_scaler.transform(test_X)
y_scaler = StandardScaler()
train_y_scaled = y_scaler.fit_transform(train_y.values.reshape(-1, 1))
test_y_scaled = y_scaler.transform(test_y.values.reshape(-1, 1))
dtr = DecisionTreeRegressor()
dtr.fit(train_X_scaled, train_y_scaled)
pred_y_scaled = dtr.predict(test_X_scaled)
print('MSE', mean_squared_error(test_y_scaled, pred_y_scaled),
'R2', r2_score(test_y_scaled, pred_y_scaled))
Note: if you want to silence the warning about int64, you can use something like this to convert to int32:
https://pandas.pydata.org/pandas-docs/version/0.22/generated/pandas.DataFrame.astype.html
df['Page total likes'] = df['Page total likes'].astype('int32')Evaluate Metrics: Regression¶
We'll now plot the learning curve for regression to see how well the decision tree performed
from sklearn.model_selection import learning_curve
def plot_learning_curve(axis, title, tr_sizes, tr_scores, val_scores):
"""Plots the learning curve for a training session
Arg:
axis: axis to plot
title: plot title
tr_sizes: sizes of the training set
tr_scores: training scores
val_scores: validation scores
"""
tr_scores_mean = np.mean(tr_scores, axis=1)
tr_scores_std = np.std(tr_scores, axis=1)
val_scores_mean = np.mean(val_scores, axis=1)
val_scores_std = np.std(val_scores, axis=1)
axis.fill_between(tr_sizes, tr_scores_mean - tr_scores_std,
tr_scores_mean + tr_scores_std, alpha=0.1,
color="r")
axis.fill_between(tr_sizes, val_scores_mean - val_scores_std,
val_scores_mean + val_scores_std, alpha=0.1, color="g")
axis.plot(tr_sizes, tr_scores_mean, 'o-', color="r",
label="Training score")
axis.plot(tr_sizes, val_scores_mean, 'o-', color="g",
label="Cross-validation score")
axis.set(title=title,
xlabel='Training examples',
ylabel='R2 Scores')
axis.grid()
axis.legend()
# Generate the learning curve for decision tree classifier, using 3-fold Cross Validation
train_sizes, train_scores, validation_scores = learning_curve(
DecisionTreeRegressor(random_state=42), train_X, train_y,
random_state=42)
fig, ax = plt.subplots(figsize=(15, 8))
plot_learning_curve(ax, 'Learning Curve: Decision Tree Regressor',
train_sizes, train_scores, validation_scores)
The Training R2 Score is constant. Can you think of a reason why?
hint: consider how a decision tree would be created on the training set
train_scores
The Validation R2 score isn't very good.
Ways to improve:
- Try Random Forest or XGBoost (typically will perform better)
- Use a non-decision tree algorithm (Linear Regression, anyone?)
validation_scores
Visualizing the Decision Tree¶
Finally, we'll visualize the decision tree.
This tree will look very complicated, because:
- There are many features
- We didn't place any limits on max_depth (which we should to make the tree more robust and less likely to overfit)
feature_names = list(balanced_df.columns)
feature_names.remove('Lifetime Post Total Reach')
target_names = 'Lifetime Post Total Reach'
filename = '../data/Facebook_metrics/facebook_likes_regressor.dot'
visualize_tree(dtr, feature_names, target_names, filename)
Optional Exercises¶
This is a loooong workshop, but if you desire to learn more about Decision Trees, try the following:
XGBoost regression
- Replace
DecisionTreeRegressor()withxgb.Regressor()with optionalGridSearchCV() - https://github.com/dmlc/xgboost/blob/master/demo/guide-python/sklearn_examples.py
- Replace
Random Forest Regressor
- Replace
DecisionTreeRegressor()withRandomForestRegressor()with optionalGridSearchCV()
- Replace
Try other Decision Tree algorithms.